 mysql
mysql
# mysql
# 什么是事务
事务是一系列操作的集合,这些操作要么全部成功,要么全部失败。
事务时一系列操作组成的工作单元,该工作单元的操作是不可分割的,要么所有操作都做,要么都不做。
事务是一系列操作组成的工作单元,该工作单元内的操作是不可分割的,即要么所有操作都做,要么所有操作都不做,这就是事务。
# DDL(数据定义语言)和DML(数据操纵语言)
# DDL包含创建修改删除表结构和数据类型的命令
# DML包括插入更新删除以及查询表中的命令
# mysql架构
# MyISAM和InnoDB区别
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录,也会锁整个表 ,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其他行有影响,适合高并发操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引,还缓存真实数据,对内存要求较高,而且内存大小对性能有决定性影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | Y | Y |
# 索引优化分析
# 性能下降SQL执行慢/执行时间长/等待时间长
- 查询语句写的烂
- 索引失效
- 单值
- 复合
- 关联查询太多join(设计缺陷或不得已的需求)
- 服务器调优以及各个参数设置(缓冲,线程数等)
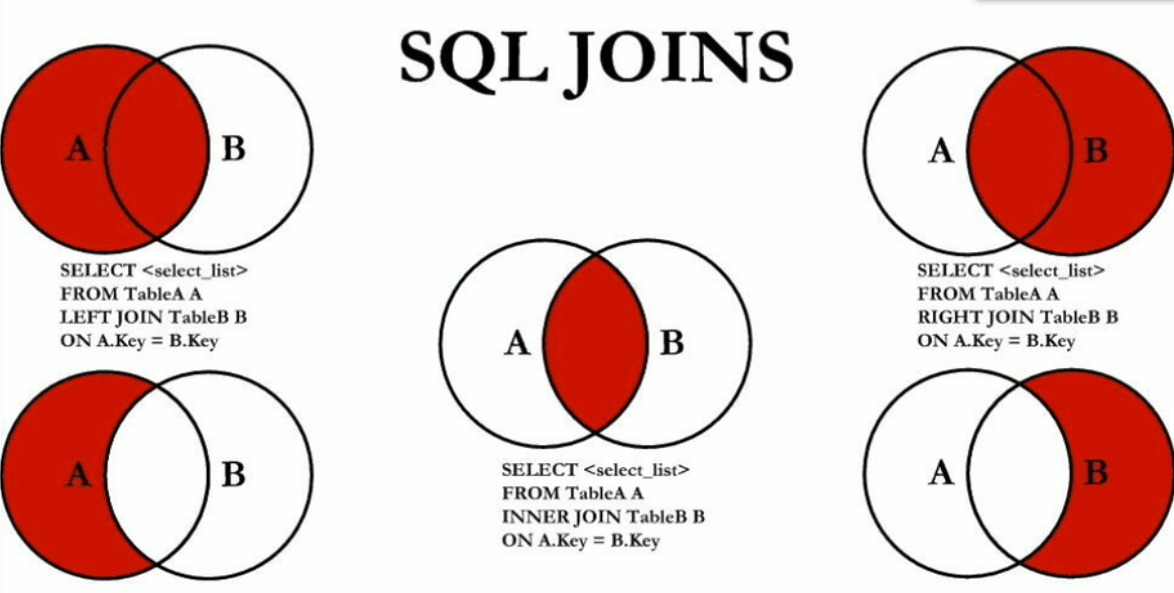
# 常见通用的Join查询
- sql执行顺序
- 手写
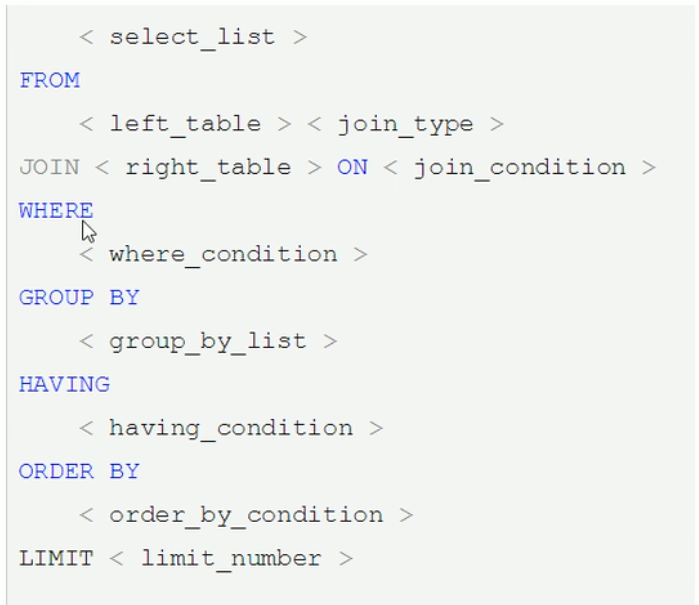
- 机读

- 总结
- 手写
- join图
- 建表sql
CREATE TABLE `t_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `address` VARCHAR(40) DEFAULT NULL, PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `t_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) DEFAULT NULL, `age` INT(3) DEFAULT NULL, `deptId` INT(11) DEFAULT NULL, empno int not null, PRIMARY KEY (`id`), KEY `idx_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO t_dept(deptName,address) VALUES('华山','华山');
INSERT INTO t_dept(deptName,address) VALUES('丐帮','洛阳');
INSERT INTO t_dept(deptName,address) VALUES('峨眉','峨眉山');
INSERT INTO t_dept(deptName,address) VALUES('武当','武当山');
INSERT INTO t_dept(deptName,address) VALUES('明教','光明顶');
INSERT INTO t_dept(deptName,address) VALUES('少林','少林寺');
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('风清扬',90,1,100001);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('岳不群',50,1,100002);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('令狐冲',24,1,100003);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('洪七公',70,2,100004);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('乔峰',35,2,100005);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('灭绝师太',70,3,100006);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('周芷若',20,3,100007);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('张三丰',100,4,100008);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('张无忌',25,5,100009);
INSERT INTO t_emp(NAME,age,deptId,empno) VALUES('韦小宝',18,null,100010);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- 7种join
1.所有有门派人员的信息(要求显示门派名称)
SELECT e.`name`,d.`deptName` FROM t_emp e INNER JOIN t_dept d ON e.`deptId`=d.`id`;
2. 列出所有人员及其门派信息
SELECT e.`name`,d.`deptName` FROM t_emp e LEFT JOIN t_dept d ON e.`deptId`=d.`id`;
3. 列出所有门派
SELECT * FROM t_dept;
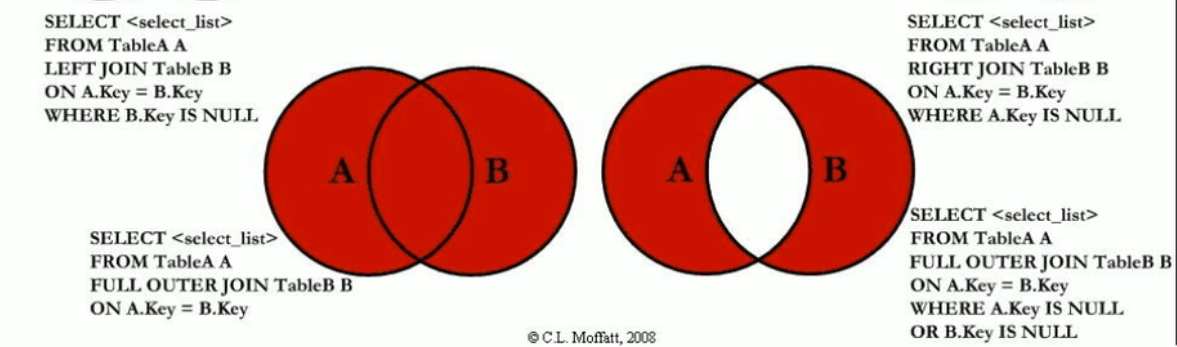
4. 所有无门派人士
SELECT * FROM t_emp WHERE deptId IS NULL;
5. 所有无人门派
SELECT d.* FROM t_dept d LEFT JOIN t_emp e ON d.`id`=e.`deptId` WHERE e.`deptId` IS NULL;
6. 所有人员和门派的对应关系
SELECT * FROM t_emp e LEFT JOIN t_dept d ON e.`deptId`=d.`id` UNION
SELECT * FROM t_emp e RIGHT JOIN t_dept d ON e.`deptId`=d.`id`;
7. 所有没有入门派的人员和没人入的门派
SELECT * FROM t_emp e LEFT JOIN t_dept d ON e.`deptId`=d.`id` WHERE e.deptId IS NULL
UNION
SELECT * FROM t_dept d LEFT JOIN t_emp e ON d.`id`=e.`deptId` WHERE e.`deptId` IS NULL;
8. 添加 CEO 字段
ALTER TABLE `t_dept` add CEO INT(11) ;
update t_dept set CEO=2 where id=1;
update t_dept set CEO=4 where id=2;
update t_dept set CEO=6 where id=3;
update t_dept set CEO=8 where id=4;
update t_dept set CEO=9 where id=5;
8.1 求各个门派对应的掌门人名称
SELECT d.deptName,e.name FROM t_dept d LEFT JOIN t_emp e ON d.ceo=e.id
8.2 求所有当上掌门人的平均年龄
SELECT AVG(e.age) FROM t_dept d LEFT JOIN t_emp e ON d.ceo=e.id
8.3 求所有人物对应的掌门名称
SELECT ed.name '人物',c.name '掌门' FROM
(SELECT e.name,d.ceo from t_emp e LEFT JOIN t_dept d on e.deptid=d.id) ed
LEFT JOIN t_emp c on ed.ceo= c.id;
SELECT e.name '人物',tmp.name '掌门' FROM t_emp e LEFT JOIN (SELECT d.id did,e.name FROM t_dept d LEFT JOIN t_emp e ON d.ceo=e.id)tmp
ON e.deptId=tmp.did;
SELECT e1.name '人物',e2.name '掌门' FROM t_emp e1
LEFT JOIN t_dept d on e1.deptid = d.id
LEFT JOIN t_emp e2 on d.ceo = e2.id ;
SELECT e2.name '人物', (SELECT e1.name FROM t_emp e1 where e1.id= d.ceo) '掌门' from t_emp e2 LEFT JOIN t_dept d on e2.deptid=d.id;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 索引简介
是什么
- MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。可以得到索引的本质:
索引是数据结构。可以简单理解为排好序的快速查找数据结构。
- 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
- 一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上
- 我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引,次要索引,覆盖索引,
- 复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。当然,除了B+树这种类型的索引之外,还有哈稀索引(hash index)等。
- MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。可以得到索引的本质:
索引是数据结构。可以简单理解为排好序的快速查找数据结构。
优势
- 提高数据检索的效率,降低数据库的IO成本
- 通过索引对数据进行的排序,降低数据排序的成本,降低了cpu的消耗
劣势
- 虽然索引大大提高了查询的速度,但是同时也降低了数据更新的速度,如对表进行insert,update,delete操作。因为更新表是,mysql不仅要更新数据,还要更新索引文件,都会调整更新所带来的的键值变化后的信息。
- 实际上也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用磁盘空间的。
- mysql的索引
- btree索引
- mysql使用的是btree索引
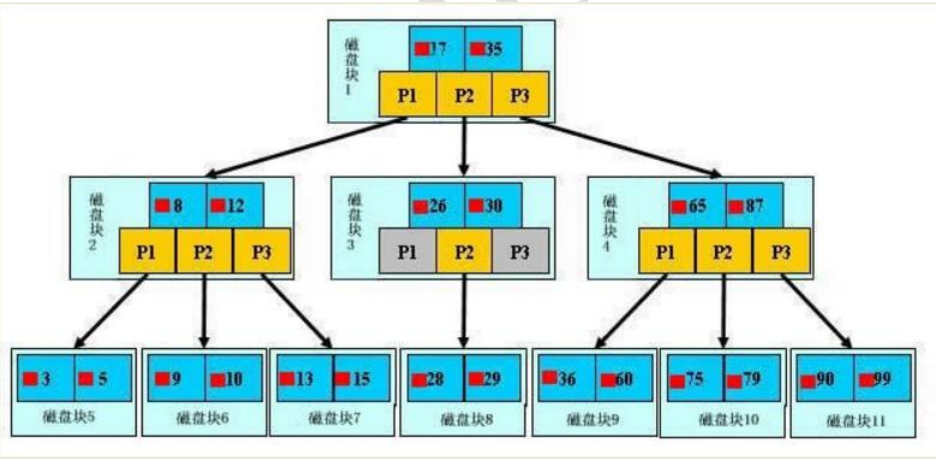
- 【初始化介绍】 一颗 b 树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色 所示),如磁盘块 1 包含数据项 17 和 35,包含指针 P1、P2、P3, P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块。 真实的数据存在于叶子节点即 3、5、9、10、13、15、28、29、36、60、75、79、90、99。 非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如 17、35 并不真实存在于数据表中。
- 【查找过程】 如果要查找数据项 29,那么首先会把磁盘块 1 由磁盘加载到内存,此时发生一次 IO,在内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,内存时间因为非常短(相比磁盘的 IO)可以忽略不计,通过磁盘块 1 的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存,发生第二次 IO,29 在 26 和 30 之间,锁定磁盘块 3 的 P2 指 针,通过指针加载磁盘块 8 到内存,发生第三次 IO,同时内存中做二分查找找到 29,结束查询,总计三次 IO。 真实的情况是,3 层的 b+树可以表示上百万的数据,如果上百万的数据查找只需要三次 IO,性能提高将是巨大的, 如果没有索引,每个数据项都要发生一次 IO,那么总共需要百万次的 IO,显然成本非常非常高。
- mysql使用的是btree索引
- b+tree索引
- 图解
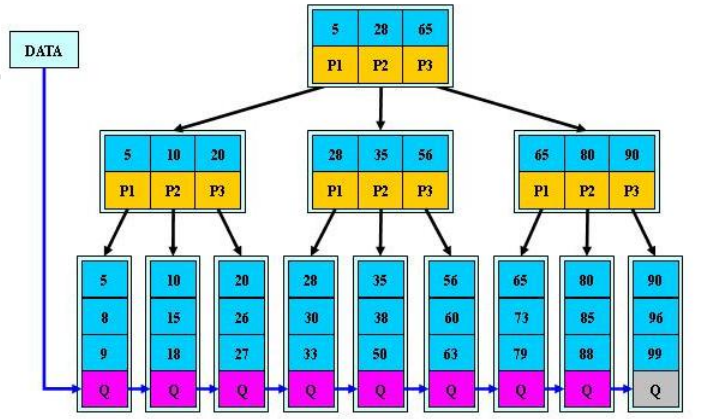
- B+Tree 与 B-Tree 的区别
- 1)B-树的关键字和记录是放在一起的,叶子节点可以看作外部节点,不包含任何信息;B+树的非叶子节点中只有关键字和指向下一个节点的索引,记录只放在叶子节点中。
- 2)在 B-树中,越靠近根节点的记录查找时间越快,只要找到关键字即可确定记录的存在;而 B+树中每个记录 的查找时间基本是一样的,都需要从根节点走到叶子节点,而且在叶子节点中还要再比较关键字。从这个角度看 B- 树的性能好像要比 B+树好,而在实际应用中却是 B+树的性能要好些。因为 B+树的非叶子节点不存放实际的数据, 这样每个节点可容纳的元素个数比 B-树多,树高比 B-树小,这样带来的好处是减少磁盘访问次数。尽管 B+树找到 一个记录所需的比较次数要比 B-树多,但是一次磁盘访问的时间相当于成百上千次内存比较的时间,因此实际中 B+树的性能可能还会好些,而且 B+树的叶子节点使用指针连接在一起,方便顺序遍历(例如查看一个目录下的所有 文件,一个表中的所有记录等),这也是很多数据库和文件系统使用 B+树的缘故。
- 思考:为什么说 B+树比 B-树更适合实际应用中操作系统的文件索引和数据库索引?
- B+树的磁盘读写代价更低 B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对 B 树更小。如果把所有同一内部结点 的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就 越多。相对来说 IO 读写次数也就降低了。
- B+树的查询效率更加稳定 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须 走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
- 图解
- 聚簇索引和非聚簇索引
- 聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。术语‘聚簇’表示数据行和相邻的键值聚簇的存储
在一起。如下图,左侧的索引就是聚簇索引,因为数据行在磁盘的排列和索引排序保持一致。
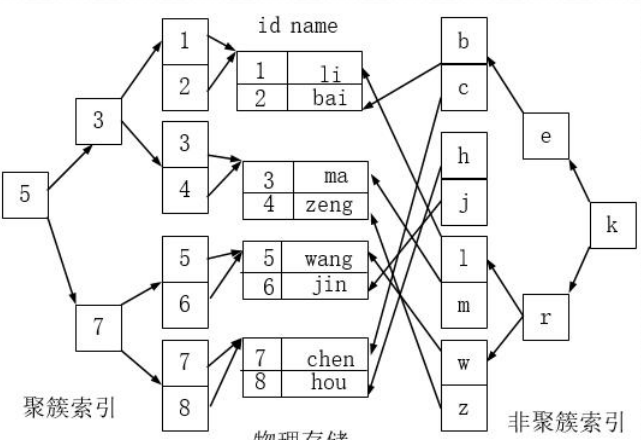
- 聚簇索引的好处: 按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不不用从多 个数据块中提取数据,所以节省了大量的 io 操作。
- 聚簇索引的限制: 对于 mysql 数据库目前只有 innodb 数据引擎支持聚簇索引,而 Myisam 并不支持聚簇索引。 由于数据物理存储排序方式只能有一种,所以每个 Mysql 的表只能有一个聚簇索引。一般情况下就是 该表的主键。 为了充分利用聚簇索引的聚簇的特性,所以 innodb 表的主键列尽量选用有序的顺序 id,而不建议用 无序的 id,比如 uuid 这种。
- 聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。术语‘聚簇’表示数据行和相邻的键值聚簇的存储
在一起。如下图,左侧的索引就是聚簇索引,因为数据行在磁盘的排列和索引排序保持一致。
- btree索引
mysql索引分类
- 单值索引 概念:即一个索引只包含单个列,一个表可以有多个单列索引 语法:
随表一起创建: CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name)); 单独建单值索引: CREATE INDEX idx_customer_name ON customer(customer_name);1
2
3
4- 唯一索引 概念:索引列的值必须唯一,但允许有空值
随表一起创建: CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no)); 单独建唯一索引: CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no);1
2
3
4- 主键索引 概念:设定为主键后数据库会自动建立索引,innodb为聚簇索引
随表一起建索引 CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200), PRIMARY KEY(id)); 单独建主键索引: ALTER TABLE customer add PRIMARY KEY customer(customer_no); 删除建主键索引: ALTER TABLE customer drop PRIMARY KEY ; 修改建主键索引: 必须先删除掉(drop)原索引,再新建(add)索引1
2
3
4
5
6
7
8- 复合索引 概念:即一个索引包含多个列
随表一起建索引: CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name)); 单独建索引: CREATE INDEX idx_no_name ON customer(customer_no,customer_name);1
2
3
4索引创建时机
- 适合创建索引
- 主键自动建立唯一索引;
- 频繁作为查询条件的字段应该创建索引
- 查询中与其它表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题, 组合索引性价比更高
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
- 不适合创建索引
- 表记录太少
- 经常增删改的表或者字段
- Where 条件里用不到的字段不创建索引
- 过滤性不好的不适合建索引
- 适合创建索引
# Explain性能分析
# 概念
- 使用 EXPLAIN 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的。分析你的查询语句或是表结构的性能瓶颈。
- 用法: Explain+SQL 语句。
- Explain 执行后返回的信息:

# Explain 准备工作
CREATE TABLE t1(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t2(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t3(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t4(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
INSERT INTO t1(content) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)));
INSERT INTO t2(content) VALUES(CONCAT('t2_',FLOOR(1+RAND()*1000)));
INSERT INTO t3(content) VALUES(CONCAT('t3_',FLOOR(1+RAND()*1000)));
INSERT INTO t4(content) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)));
2
3
4
5
6
7
8
# id
- select 查询的序列号,包含一组数字,表示查询中执行 select 子句或操作表的顺序。
- ①id 相同,执行顺序由上至下

- ②id 不同,id 不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行

- ③有相同也有不同
 id 如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id 值越大,优先级越高,越先执行衍生 = DERIVED
关注点:id 号每个号码,表示一趟独立的查询。一个 sql 的查询趟数越少越好。
id 如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id 值越大,优先级越高,越先执行衍生 = DERIVED
关注点:id 号每个号码,表示一趟独立的查询。一个 sql 的查询趟数越少越好。
# select_type
- select_type 代表查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
| select_type 属性 | 含义 |
|---|---|
| SIMPLE | 简单的 select 查询,查询中不包含子查询或者 UNION |
| PRIMARY | 查询中若包含任何复杂的子部分,最外层查询则被标记为 Primary |
| DERIVED | 在 FROM 列表中包含的子查询被标记为 DERIVED(衍生) MySQL 会递归执行这些子查询, 把结果放在临时表里。 |
| SUBQUERY | 在SELECT或WHERE列表中包含了子查询 |
| DEPEDENT SUBQUERY | 在SELECT或WHERE列表中包含了子查询,子查询基于外层 |
| UNCACHEABLE SUBQUERY | 无法使用缓存的子查询 |
| UNION | 若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
# table
- 这个数据是基于哪张表的。
# type
- type 是查询的访问类型。是较为重要的一个指标,结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL ,一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
# system
是const的特例 表里结果集只有一行记录
# const
常数行 用primarykey或uniquekey所有列与常数比较时,只有一条结果
# eq_ref
primarykey或uniquekey的所有部分被连接使用,最多只会返回一条符合条件的记录
# ref
相比eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要与常量比较 简单查询,用了普通索引,但返回的结果多于一条 关联表查询,联合索引只用了左边前缀
# range
范围扫描,出现在in(),between and,>,<,like等操作中
# index
全索引扫描,索引树中扫描,比ALL快,因为索引文件通常比数据文件小。
# all
全表扫描,扫描聚簇索引所有的叶子节点
# possible_keys
- 显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
# key
- 实际使用的索引。如果为NULL,则没有使用索引。
# key_len
- 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。 key_len 字段能够帮你检查是否充分的利用上了索引。ken_len 越长,说明索引使用的越充分。
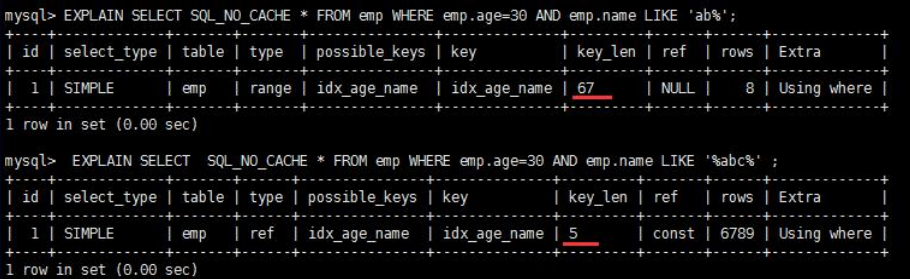
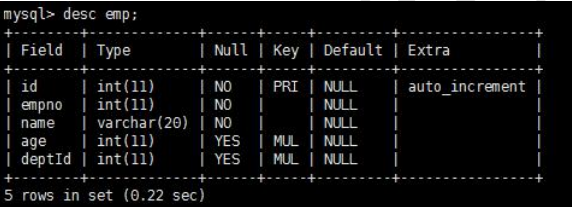
- 如何计算:
- ①先看索引上字段的类型+长度比如 int=4 ; varchar(20) =20 ; char(20) =20
- ②如果是 varchar 或者 char 这种字符串字段,视字符集要乘不同的值,比如 utf-8 要乘 3,GBK 要乘 2
- ③varchar 这种动态字符串要加 2 个字节
- ④允许为空的字段要加 1 个字节
- 第一组:key_len=age 的字节长度+name 的字节长度=4+1 + ( 20*3+2)=5+62=67
- 第二组:key_len=age 的字节长度=4+1=5
# ref
- 显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。

# rows
- rows 列显示 MySQL 认为它执行查询时必须检查的行数。越少越好!

# Extra
其他的额外重要的信息。
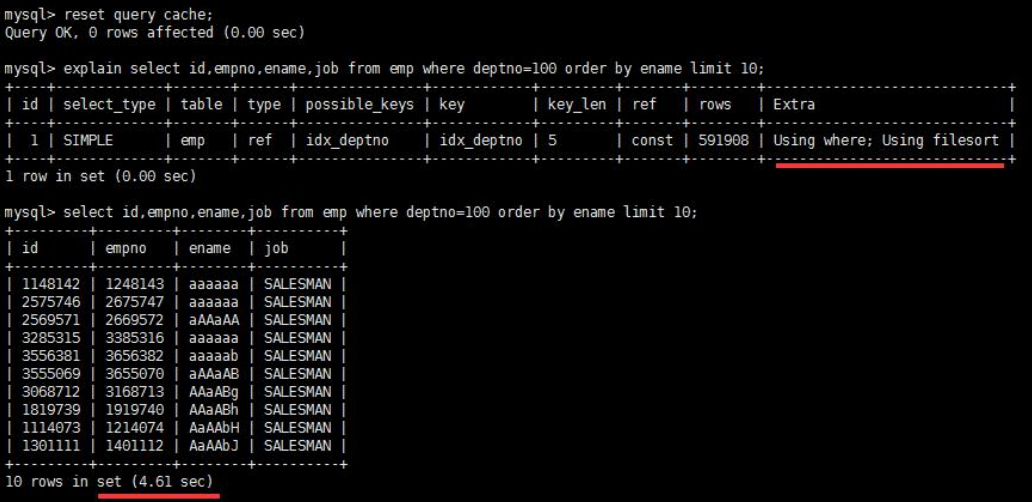
Using filesort
- 说明 mysql 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL 中无法利用索引完成的排序操作称为“文件排序”。
- 出现 filesort 的情况:
 优化后
优化后
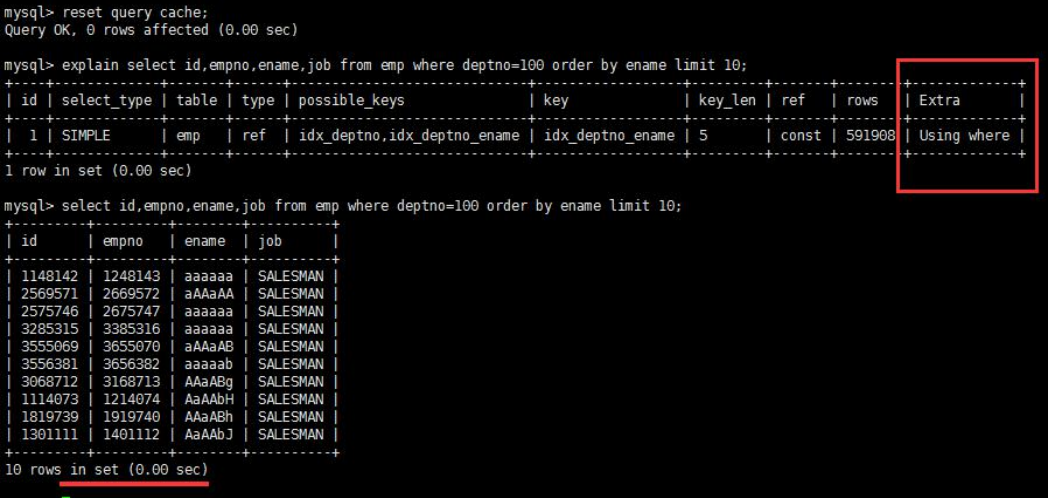 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。
Using temporary -使了用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。
- 优化前:
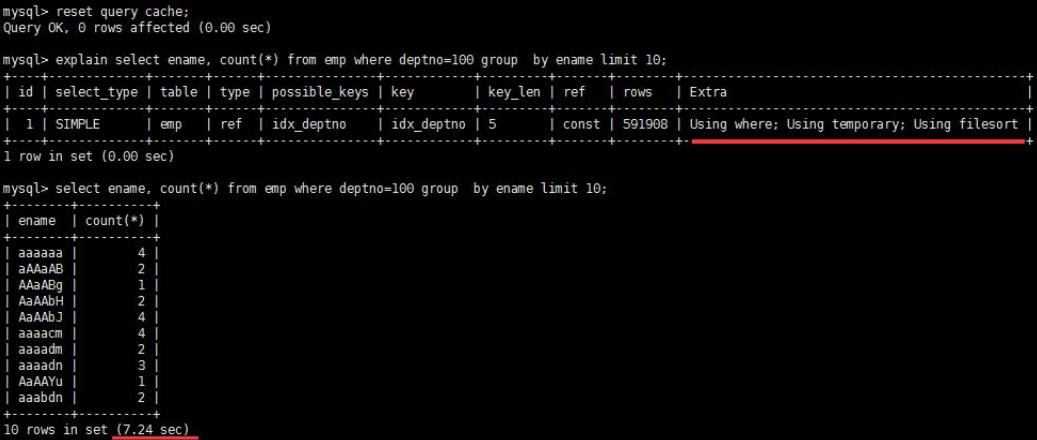
- 优化后:
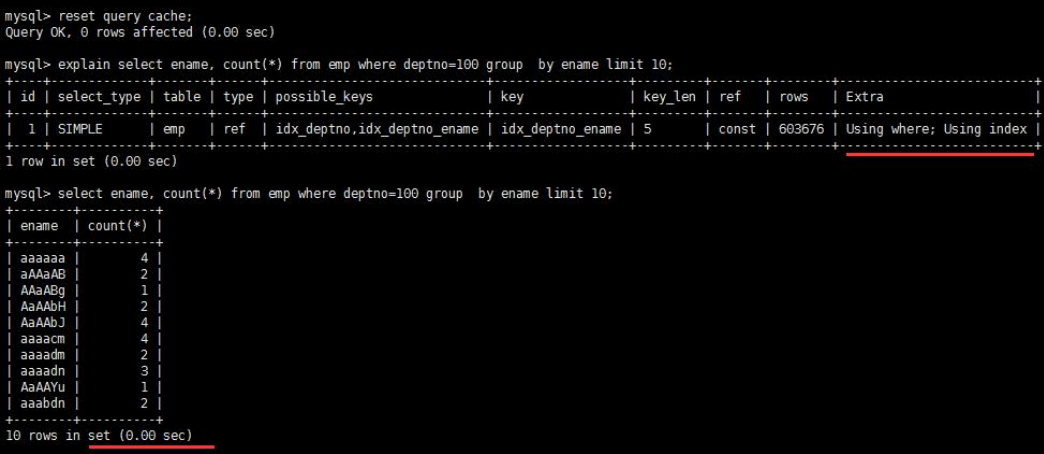
- 优化前:
Using index
- Using index 代表表示相应的 select 操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错! 如果同时出现 using where,表明索引被用来执行索引键值的查找;如果没有同时出现 using where,表明索引只是用来读取数据而非利用索引执行查找。
- 利用索引进行了排序或分组。
Using where
- 表明使用了 where 过滤
Using join buffer

impossible where
- where 子句的值总是 false,不能用来获取任何元组。

- where 子句的值总是 false,不能用来获取任何元组。
select tables optimized away
- 在没有 GROUPBY 子句的情况下,基于索引优化 MIN/MAX 操作或者对于 MyISAM 存储引擎优化 COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
- 在innodb中

- 在myisam中

# 常见索引失效以及优化
# 前期准备
- 设置参数
- 在执行创建函数之前,首先请保证 log_bin_trust_function_creators 参数为 1,即 on 开启状态。否则会报错:
- 查询:show variables like 'log_bin_trust_function_creators';
- 设置:set global log_bin_trust_function_creators=1;
- 当然,如上设置只存在于当前操作,想要永久生效,需要写入到配置文件中:
- 在[mysqld]中加上 log_bin_trust_function_creators=1
- 创建表
CREATE TABLE `dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `address` VARCHAR(40) DEFAULT NULL, ceo INT NULL , PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT, `empno` INT NOT NULL , `name` VARCHAR(20) DEFAULT NULL, `age` INT(3) DEFAULT NULL, `deptId` INT(11) DEFAULT NULL, PRIMARY KEY (`id`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2
3
4
5
6
7
8
编写随机函数
- 随机产生字符串、
DELIMITER $$ CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) BEGIN DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i + 1; END WHILE; RETURN return_str; END $$1
2
3
4
5
6
7
8
9
10
11
12- 随机产生部门编号
DELIMITER $$ CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11) BEGIN DECLARE i INT DEFAULT 0; SET i = FLOOR(from_num +RAND()*(to_num -from_num+1)) ; RETURN i; END$$1
2
3
4
5
6
7创建存储过程
- 创建往 emp 表中插入数据的存储过程
DELIMITER $$ CREATE PROCEDURE insert_emp( START INT , max_num INT ) BEGIN DECLARE i INT DEFAULT 0; #set autocommit =0 把 autocommit 设置成 0 SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO emp (empno, NAME ,age ,deptid ) VALUES ((START+i) ,rand_string(6) , rand_num(30,50),rand_num(1,10000)); UNTIL i = max_num END REPEAT; COMMIT; END$$ #删除 # DELIMITER ; # drop PROCEDURE insert_emp;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17- 创建往 dept 表中插入数据的存储过程
#执行存储过程,往 dept 表添加随机数据 DELIMITER $$ CREATE PROCEDURE `insert_dept`( max_num INT ) BEGIN DECLARE i INT DEFAULT 0; SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO dept ( deptname,address,ceo ) VALUES (rand_string(8),rand_string(10),rand_num(1,500000)); UNTIL i = max_num END REPEAT; COMMIT; END$$ #删除 # DELIMITER ; # drop PROCEDURE insert_dept;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17调用存储过程
- 添加数据到部门表
DELIMITER ; CALL insert_dept(10000);1
2- 添加数据到员工表
DELIMITER ; CALL insert_emp(100000,500000);1
2批量删除某个表上的所有索引
- 删除索引的存储过程
DELIMITER $$ CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200)) BEGIN DECLARE done INT DEFAULT 0; DECLARE ct INT DEFAULT 0; DECLARE _index VARCHAR(200) DEFAULT ''; DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ; DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ; OPEN _cur; FETCH _cur INTO _index; WHILE _index<>'' DO SET @str = CONCAT("drop index ",_index," on ",tablename ); PREPARE sql_str FROM @str ; EXECUTE sql_str; DEALLOCATE PREPARE sql_str; SET _index=''; FETCH _cur INTO _index; END WHILE; CLOSE _cur; END$$1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21- 执行存储过程
#调用: DELIMITER $$ CALL proc_drop_index("dbname","tablename");1
2
3
# 全值匹配我最爱
- 有以下sql
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4
EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = 'abcd'
2
3
- 建立索引
CREATE INDEX idx_age_deptid_name ON emp(age,deptid,NAME);


结论:
- 全值匹配我最爱指的是,查询的字段按照顺序在索引中都可以匹配到
- sql中查询字段的顺序,跟使用索引中字段的顺序,没有关系。优化器会在不影响sql执行的前提下,自动优化。
# 最佳左前缀法则
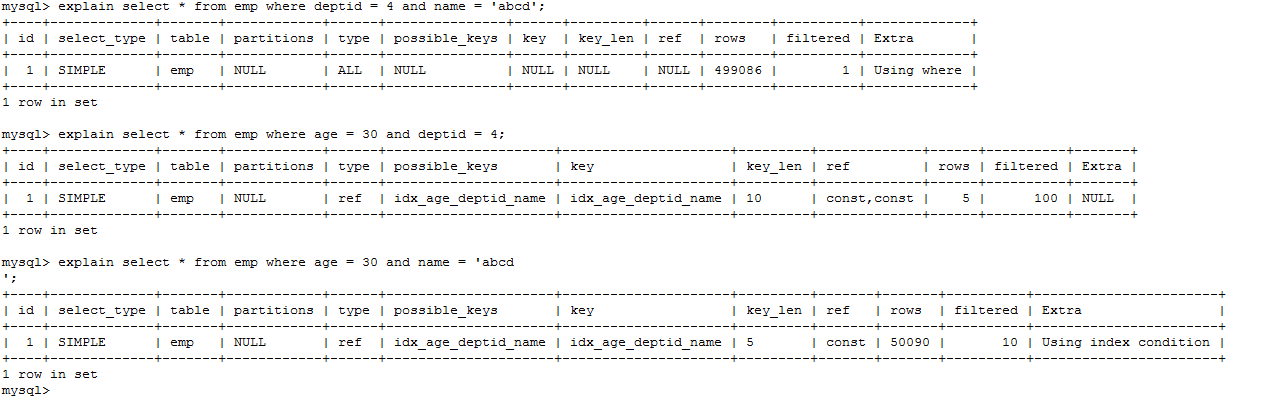
- 查询字段与索引字段顺序的不同会导致,索引无法充分使用,甚至索引失效!
- 原因:使用复合索引,需要遵循最佳左前缀法则,即如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
- 结论:过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
# 不要在索引列上做任何计算
不在索引列上做任何操作(计算、函数、(自动 or 手动)类型转换),会导致索引失效而转向全表扫描。
- 在查询列上使用了函数
explain select * from emp where age = 30;
explain select * from emp where LEFT(age,3) = 30;
2
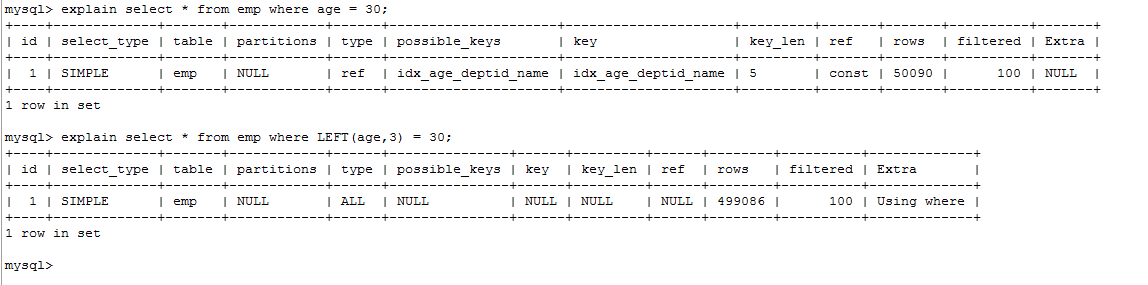
结论:等号左边无计算!
- 在查询列上做了转换
create index idx_name on emp(name);
explain select * from emp where name = '30000';
explain select * from emp where name = 30000;
2
3
字符串不加单引号,则会在 name 列上做一次转换!
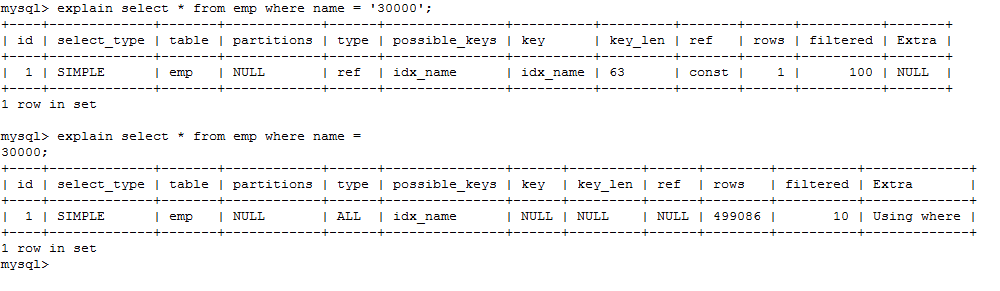
结论:等号右边无转换!
# 索引列上不能有范围查询
explain select * from emp where age = 30 and deptid = 5 and name = 'abcd';
explain select * from emp where age = 30 and deptid <= 5 and name = 'abcd';
2
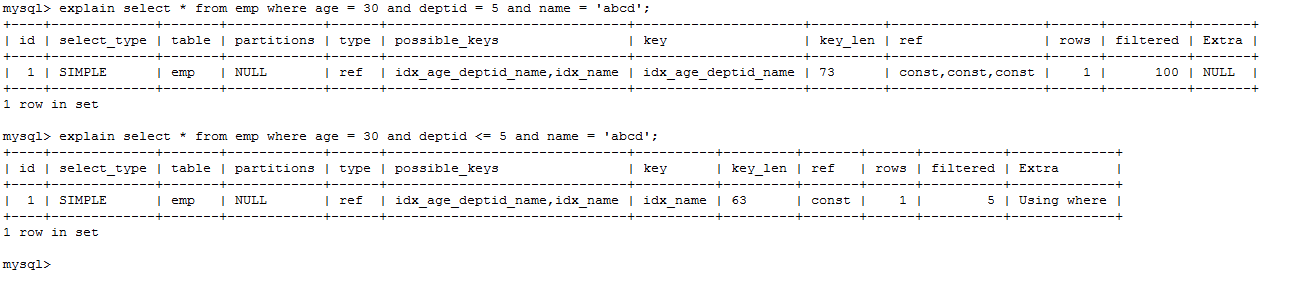
建议:将可能做范围查询的字段的索引顺序放在最后
# 尽量使用覆盖索引
explain select * from emp where age = 30 and deptid = 5 and name = 'abcd';
explain select age,deptid,name from emp where age = 30 and deptid = 5 and name = 'abcd';
2

即查询列和索引列一致,不要写 select *!
# 使用不等于(!= 或者<>)的时候
explain select * from emp where age = 30;
explain select * from emp where age != 30;
2
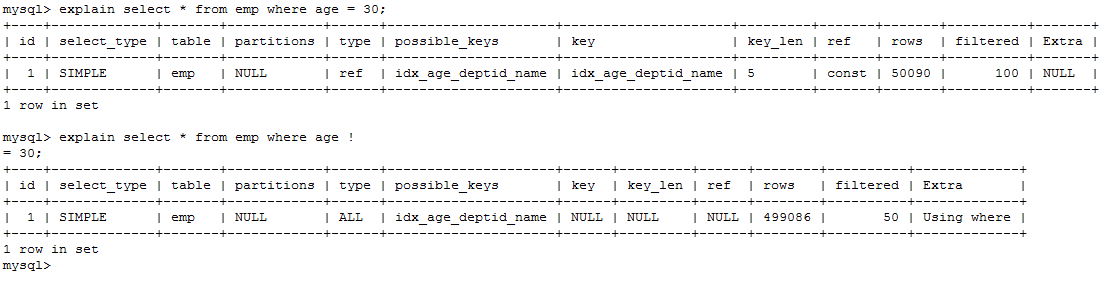
mysql 在使用不等于(!= 或者<>)时,有时会无法使用索引会导致全表扫描。
# 字段的 is not null 和 is null

当字段允许为 Null 的条件下: is not null 用不到索引,is null 可以用到索引。
# like 的前后模糊匹配
explain select * from emp where name like '%a';
explain select * from emp where name like '%a%';
explain select * from emp where name like 'a%';
2
3
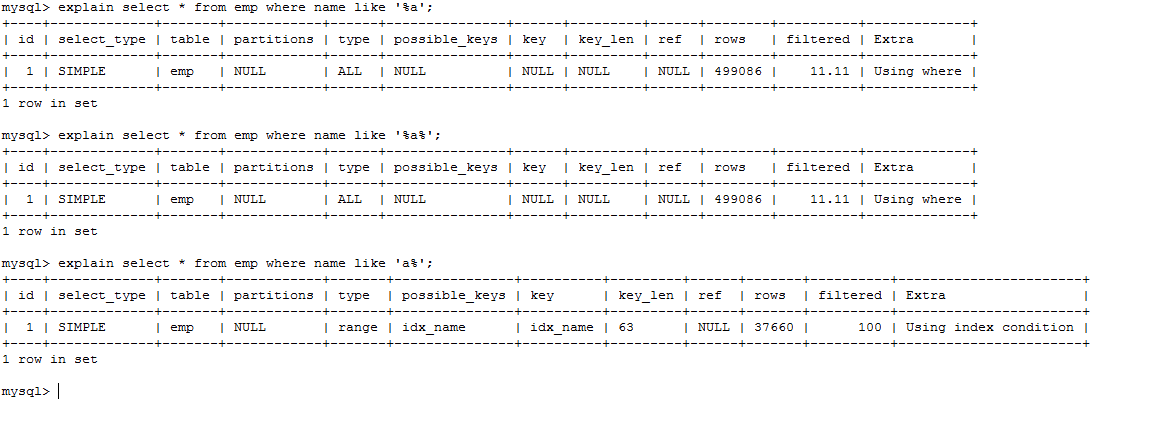
前缀不能出现模糊匹配!
# 减少使用 or
explain select * from emp where age = 30 or age = 40;
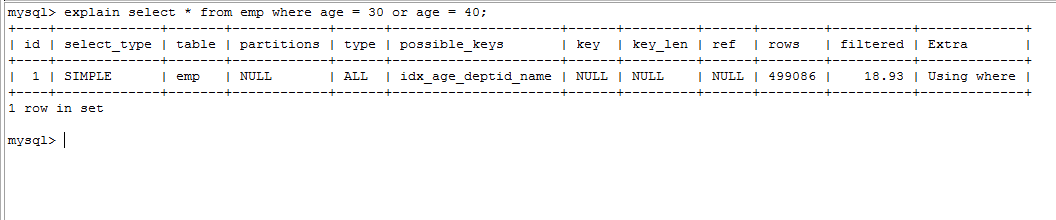
使用 union all 或者 union 来替代:
explain select * from emp where age = 30 union select * from emp where age = 40;

# 口诀
全职匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
LIKE 百分写最右,覆盖索引不写*;
不等空值还有 OR,索引影响要注意;
VAR 引号不可丢,SQL 优化有诀窍。
2
3
4
5
6
# 关联查询优化
# 关联查询优化前期准备
- 建表语句
CREATE TABLE IF NOT EXISTS `class` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`id`)
);
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`bookid`)
);
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 案例
- left join
①EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
 ②如何优化?在哪个表上建立索引?
alter table book add index idx_card(card);
②如何优化?在哪个表上建立索引?
alter table book add index idx_card(card);
 ③删除 book 表的索引:drop index idx_card on book;
在 class 表上建立索引:alter table class add index idx_card(card);
③删除 book 表的索引:drop index idx_card on book;
在 class 表上建立索引:alter table class add index idx_card(card);
 结论:
①在优化关联查询时,只有在被驱动表上建立索引才有效!
②left join 时,左侧的为驱动表,右侧为被驱动表!
结论:
①在优化关联查询时,只有在被驱动表上建立索引才有效!
②left join 时,左侧的为驱动表,右侧为被驱动表!
- inner join
①EXPLAIN SELECT * FROM book inner join class on class.card=book.card;
 ②两个查询表调换顺序,发现结果也是一样的!
②两个查询表调换顺序,发现结果也是一样的!
 ③在 book 表中,删除 9 条记录
③在 book 表中,删除 9 条记录

 ④结论:inner join 时,mysql 会自己帮你把小结果集的表选为驱动表。
④结论:inner join 时,mysql 会自己帮你把小结果集的表选为驱动表。
 ⑤straight_join: 效果和 inner join 一样,但是会强制将左侧作为驱动表!
⑤straight_join: 效果和 inner join 一样,但是会强制将左侧作为驱动表!
- 四个关联查询案例分析
explain select ed.name '人物',c.name '掌门' from (select e.name,d.ceo from t_emp e left join t_dept d on e.deptid = d.id) ed left join t_emp c on ed.ceo = c.id;
 explain select e.name '人物',tmp.name '掌门' from t_emp e left join (select d.id did,e.name from t_dept d left join t_emp e on d.ceo = e.id) tmp on e.deptid = tmp.did;
explain select e.name '人物',tmp.name '掌门' from t_emp e left join (select d.id did,e.name from t_dept d left join t_emp e on d.ceo = e.id) tmp on e.deptid = tmp.did;
 上述两个案例,第一个查询效率较高,且有优化的余地。第二个案例中,子查询作为被驱动表,由于子查询是虚表,
无法建立索引,因此不能优化。
上述两个案例,第一个查询效率较高,且有优化的余地。第二个案例中,子查询作为被驱动表,由于子查询是虚表,
无法建立索引,因此不能优化。
结论: 子查询尽量不要放在被驱动表,有可能使用不到索引; left join时,尽量让实体表作为被驱动表。
EXPLAIN SELECT e1.name '人物',e2.name '掌门' FROM t_emp e1
LEFT JOIN t_dept d on e1.deptid = d.id
LEFT JOIN
 Explain SELECT e2.name '人物', (SELECT e1.name FROM t_emp e1 where e1.id= d.ceo) '掌门' from t_emp e2 LEFT JOIN
Explain SELECT e2.name '人物', (SELECT e1.name FROM t_emp e1 where e1.id= d.ceo) '掌门' from t_emp e2 LEFT JOIN

结论:能够直接多表关联的尽量直接关联,不用子查询!
# 子查询优化
# 子查询优化案例
取所有不为掌门人的员工,按年龄分组!
explain select age as '年龄',count() as '人数' from t_emp where id not in (select ceo from t_dept where ceo is not null) group by age;
 如何优化?
①解决 dept 表的全表扫描,建立 ceo 字段的索引:
如何优化?
①解决 dept 表的全表扫描,建立 ceo 字段的索引:
 ②进一步优化,替换 not in。
上述 SQL 可以替换为:
explain select age as '年龄',count() as '人数' from t_emp e left join t_dept d on e.id=d.ceo where d.id is null group by age;
②进一步优化,替换 not in。
上述 SQL 可以替换为:
explain select age as '年龄',count() as '人数' from t_emp e left join t_dept d on e.id=d.ceo where d.id is null group by age;
 结论: 在范围判断时,尽量不要使用 not in 和 not exists,使用 left join on xxx is null 代替。
结论: 在范围判断时,尽量不要使用 not in 和 not exists,使用 left join on xxx is null 代替。
# 排序分组优化
where 条件和 on 的判断这些过滤条件,作为优先优化的部分,是要被先考虑的!其次,如果有分组和排序,那么也要考虑 grouo by 和 order by。
# 无过滤不索引
create index idx_age_deptid_name on emp (age,deptid,name);
explain select * from emp where age=40 order by deptid;
explain select * from emp order by age,deptid;
explain select * from emp order by age,deptid limit 10;
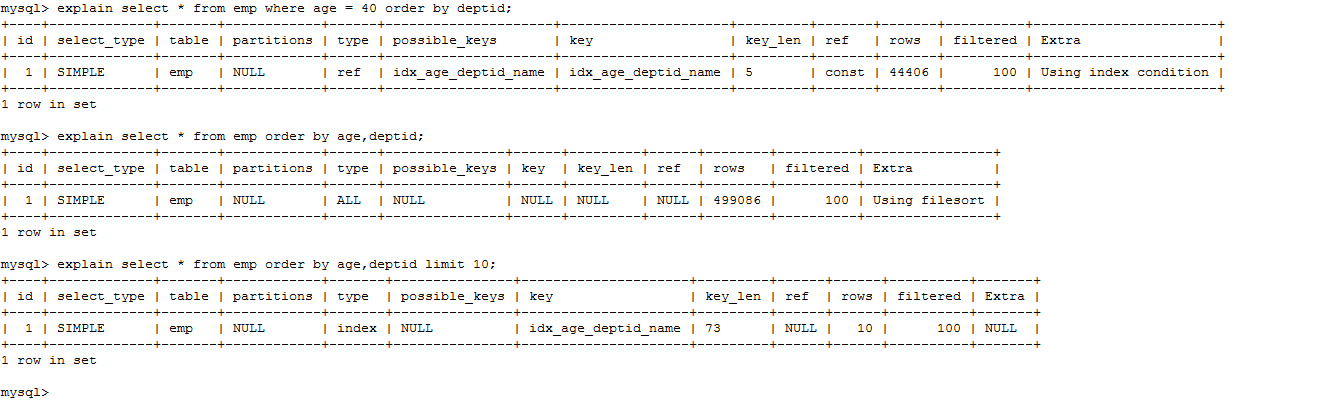 using filesort 说明进行了手工排序!原因在于没有 where 作为过滤条件!
结论: 无过滤,不索引。where,limt 都相当于一种过滤条件,所以才能使用上索引!
using filesort 说明进行了手工排序!原因在于没有 where 作为过滤条件!
结论: 无过滤,不索引。where,limt 都相当于一种过滤条件,所以才能使用上索引!
# 顺序错,必排序
①explain select from emp where age=45 order by deptid,name;
 ②explain selectfrom emp where age=45 order by deptid,empno;
②explain selectfrom emp where age=45 order by deptid,empno;
 empno 字段并没有建立索引,因此也无法用到索引,此字段需要排序!
③explain select from emp where age=45 order by name,deptid;
empno 字段并没有建立索引,因此也无法用到索引,此字段需要排序!
③explain select from emp where age=45 order by name,deptid;
 ④explain selectfrom emp where deptid=45 order by age;
where 两侧列的顺序可以变换,效果相同,但是 order by 列的顺序不能随便变换!
④explain selectfrom emp where deptid=45 order by age;
where 两侧列的顺序可以变换,效果相同,但是 order by 列的顺序不能随便变换!
 deptid 作为过滤条件的字段,无法使用索引,因此排序没法用上索引
deptid 作为过滤条件的字段,无法使用索引,因此排序没法用上索引
# 方向反,必排序
①explain selectfrom emp where age=45 order by deptid desc, name desc ;
 如果可以用上索引的字段都使用正序或者逆序,实际上是没有任何影响的,无非将结果集调换顺序。
②explain selectfrom emp where age=45 order by deptid asc, name desc ;
如果可以用上索引的字段都使用正序或者逆序,实际上是没有任何影响的,无非将结果集调换顺序。
②explain selectfrom emp where age=45 order by deptid asc, name desc ;
 如果排序的字段,顺序有差异,就需要将差异的部分,进行一次倒置顺序,因此还是需要手动排序的!
如果排序的字段,顺序有差异,就需要将差异的部分,进行一次倒置顺序,因此还是需要手动排序的!
# 索引的选择
- ①首先,清除 emp 上面的所有索引,只保留主键索引! drop index idx_age_deptid_name on emp;
- ②查询:年龄为 30 岁的,且员工编号小于 101000 的用户,按用户名称排序
explain SELECT SQL_NO_CACHE * FROM emp WHERE age =30 AND empno <101000 ORDER BY NAME ;

- ③全表扫描肯定是不被允许的,因此我们要考虑优化。
思路:首先需要让 where 的过滤条件,用上索引;
查询中,age.empno 是查询的过滤条件,而 name 则是排序的字段,因此我们来创建一个此三个字段的复合索引:
create index idx_age_empno_name on emp(age,empno,name);
 再次查询,发现 using filesort 依然存在。
原因: empno 是范围查询,因此导致了索引失效,所以 name 字段无法使用索引排序。
所以,三个字段的符合索引,没有意义,因为 empno 和 name 字段只能选择其一!
再次查询,发现 using filesort 依然存在。
原因: empno 是范围查询,因此导致了索引失效,所以 name 字段无法使用索引排序。
所以,三个字段的符合索引,没有意义,因为 empno 和 name 字段只能选择其一! - ④解决: 鱼与熊掌不可兼得,因此,要么选择 empno,要么选择 name
drop index idx_age_empno_name on emp;
create index idx_age_name on emp(age,name);
create index idx_age_empno on emp(age,empno);
两个索引同时存在,mysql 会选择哪个?
 explain SELECT SQL_NO_CACHE * FROM emp use index(idx_age_name) WHERE age =30 AND empno <101000 ORDER BY NAME ;
explain SELECT SQL_NO_CACHE * FROM emp use index(idx_age_name) WHERE age =30 AND empno <101000 ORDER BY NAME ;

- 原因:所有的排序都是在条件过滤之后才执行的,所以如果条件过滤了大部分数据的话,几百几千条数据进行排序其实并不是很消耗性能,即使索引优化了排序但实际提升性能很有限。 相对的 empno<101000 这个条件如果没有用到索引的话,要对几万条的数据进行扫描,这是非常消耗性能的,使用 empno 字段的范围查询,过滤性更好(empno 从 100000 开始)!
- 结论: 当范围条件和 group by 或者 order by 的字段出现二选一时 ,优先观察条件字段的过滤数量,如果过滤的数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
# using filesort
- mysql 的排序算法
- ①双路排序
- MySQL 4.1 之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,读取行指针和 orderby 列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。
- 从磁盘取排序字段,在 buffer 进行排序,再从磁盘取其他字段。
- 简单来说,取一批数据,要对磁盘进行了两次扫描,众所周知,I\O 是很耗时的,所以在 mysql4.1 之后,出现了第二种改进的算法,就是单路排序。
- ②单路排序
- 从磁盘读取查询需要的所有列,按照 order by 列在 buffer 对它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。并且把随机 IO 变成了顺序 IO,但是它会使用更多的空间,因为它把每一行都保存在内存中了。
- ③单路排序的问题
- 由于单路是后出的,总体而言好过双路。但是存在以下问题: 在 sort_buffer 中,方法 B 比方法 A 要多占用很多空间,因为方法 B 是把所有字段都取出, 所以有可能取出的数据的总大小超出了 sort_buffer 的容量,导致每次只能取 sort_buffer 容量大小的数据,进行排序(创建 tmp 文件,多路合并),排完再取取 sort_buffer 容量大小,再排……从而多次 I/O。 结论:本来想省一次 I/O 操作,反而导致了大量的 I/O 操作,反而得不偿失。
- ①双路排序
- 如何优化
①增大 sort_butter_size 参数的设置
- 不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的 1M-8M 之间调整。 ②增大 max_length_for_sort_data 参数的设置
- mysql 使用单路排序的前提是排序的字段大小要小于 max_length_for_sort_data。 提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出 sort_buffer_size 的概率就增大, 明显症状是高的磁盘 I/O 活动和低的处理器使用率。(1024-8192 之间调整)。 ③减少 select 后面的查询的字段。
- 当 Query 的字段大小总和小于 max_length_for_sort_data 而且排序字段不是 TEXT|BLOB 类型时,会用改进后的 算法——单路排序, 否则用老算法——多路排序。
- 两种算法的数据都有可能超出 sort_buffer 的容量,超出之后,会创建 tmp 文件进行合并排序,导致多次 I/O, 但是用单路排序算法的风险会更大一些,所以要提高 sort_buffer_size。
# 使用覆盖索引
- 覆盖索引:SQL 只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。
# group by
group by 使用索引的原则几乎跟 order by 一致 ,唯一区别是 group by 即使没有过滤条件用到索引,也可以直接使用索引。
# 截取查询分析
# 慢查询分析
是什么
- MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。
- 具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10秒以上的语句。
- 由他来查看哪些SQL超出了我们的最大忍耐时间值,比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合之前explain进行全面分析。
怎么用
- 默认情况下,MySQL 数据库没有开启慢查询日志,需要我们手动来设置这个参数。
- 当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件。
- 开启设置
SQL 语句 描述 备注 SHOW VARIABLES LIKE '%slow_query_log%'; 查看慢查询日志是否开启 默认情况下 slow_query_log 的值为 OFF,表示慢查询日志是禁用的 set global slow_query_log=1; 开启慢查询日志 备注 SHOW VARIABLES LIKE 'long_query_time%'; 查看慢查询设定阈值 单位秒 set long_query_time=1 设定慢查询阈值 单位秒 - 如永久生效需要修改配置文件 my.cnf 中[mysqld]下配置
[mysqld] slow_query_log=1 slow_query_log_file=/var/lib/mysql/atguigu-slow.log long_query_time=3 log_output=FILE1
2
3
4
5运行查询时间长的 sql,打开慢查询日志查看
日志分析工具 mysqldumpslow
- 查看mysqldumpslow的帮助信息
- mysqldumpslow --help
- 查看mysqldumpslow的帮助信息
得到返回记录集最多的 10 个 SQL mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log 得到访问次数最多的 10 个 SQL mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log 得到按照时间排序的前 10 条里面含有左连接的查询语句 mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/atguigu-slow.log 另外建议在使用这些命令时结合 | 和 more 使用 ,否则有可能出现爆屏情况 mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more1
2
3
4
5
6
7
8- 查看mysqldumpslow的帮助信息
# SHOW PROCESSLIST
- 是什么
- 查询 mysql 进程列表,可以杀掉故障进程
- 怎么用
- show processlist;
- kill pid;
# 主从复制
# 复制的基本原理
- slave 会从 master 读取 binlog 来进行数据同步
- 三步骤+原理图
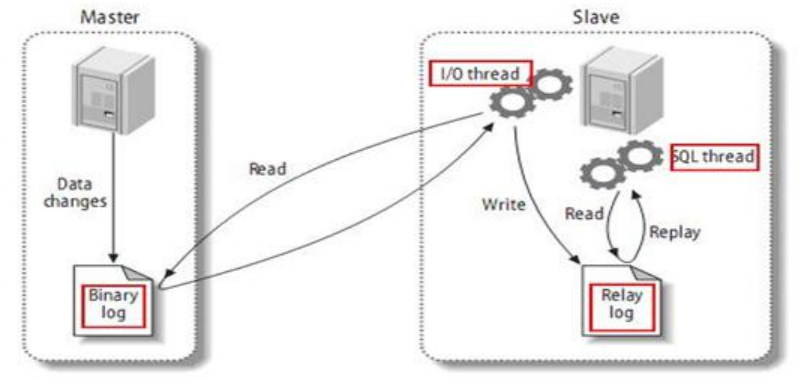 MySQL 复制过程分成三步:
MySQL 复制过程分成三步:
- master 将改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events;
- slave 将 master 的 binary log events 拷贝到它的中继日志(relay log);
- slave 重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL 复制是异步的且串行化的
# 复制的基本原则
- 每个 slave 只有一个 master
- 每个 slave 只能有一个唯一的服务器 ID
- 每个 master 可以有多个 salve
# 复制的最大问题
- 因为发生多次 IO,存在延时问题
# 一主一从常见配置
mysql 版本一致且后台以服务运行
主从都配置在[mysqld]结点下,都是小写 主机修改 my.ini 配置文件
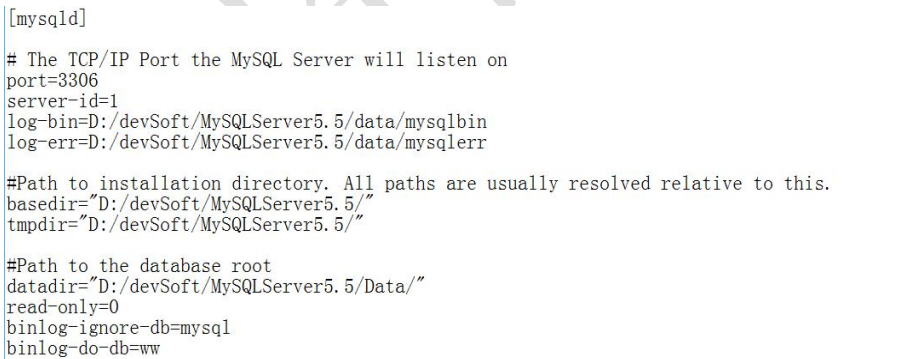
主服务器唯一 ID server-id=1 启用二进制日志 log-bin=自己本地的路径/data/mysqlbin log-bin=D:/devSoft/MySQLServer5.5/data/mysqlbin 设置不要复制的数据库 binlog-ignore-db=mysql 设置需要复制的数据库 binlog-do-db=需要复制的主数据库名字 设置 logbin 格式 binlog_format=STATEMENT(默认)1
2
3
4
5
6
7
8
9
10
11mysql 主从复制起始时,从机不继承主机数据
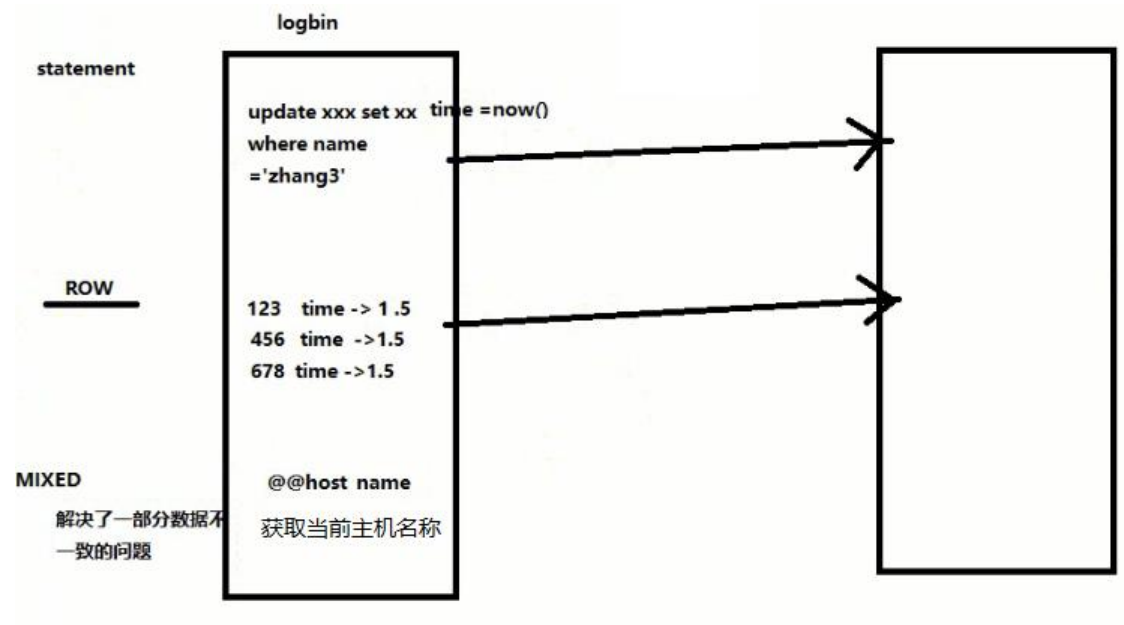
logbin 格式
binlog_format=STATEMENT(默认)
binlog_format=ROW
binlog_format=MIXED
2
3
- 从机配置文件修改 my.cnf 的[mysqld]栏位下
#从机服务 id
server-id = 2
#注意 my.cnf 中有 server-id = 1
#设置中继日志
relay-log=mysql-relay
2
3
4
5
- 因修改过配置文件,请主机+从机都重启后台 mysql 服务
- 主机从机都关闭防火墙、安全工具(腾讯管家等)
- 在 Windows 主机上建立帐户并授权 slave
#创建用户,并授权
GRANT REPLICATION SLAVE ON *.* TO '备份账号'@'从机器数据库 IP' IDENTIFIED BY '123456';
2
- 查询 master 的状态,并记录下 File 和 Position 的值
#查询 master 的状态
show master status;
2
执行完此步骤后不要再操作主服务器 MYSQL,防止主服务器状态值变化
- 在 Linux 从机上配置需要复制的主机
#查询 master 的状态
CHANGE MASTER TO MASTER_HOST='主机 IP',MASTER_USER='创建用户名',MASTER_PASSWORD='创建的密码', MASTER_LOG_FILE='File 名字',MASTER_LOG_POS=Position 数字;
2
- 启动从服务器复制功能
start slave;
show slave status\G;
2
下面两个参数都是 Yes,则说明主从配置成功!
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
2
- 主机新建库、新建表、insert 记录,从机复制
- 如何停止从服务复制功能
stop slave;
# 速查表
show index from table_name CREATE INDEX idx_name ON table_name(column_name); alter table table_name add index idx_name(column_name); drop index idx_name on table_name;
# 事务
# 事务的 ACID
- 原子性(Atomicity):当前事务要么同时成功,要么同时失败。由undo log日志实现
- 一致性(Consistency):使用事务的最终目的,由其他3个特性保证以及业务代码正确逻辑来实现
- 隔离性(Isolation):在事务并发执行时,他们内部的操作不能互相干扰。由锁以及MVCC实现
- 持久性(Durability):一旦事务提交,数据将永久保存在数据库中。由redo log日志实现
# 事务的隔离级别
# 读未提交(Read uncommitted)
没有视图概念,都是返回最新的数据 会导致脏读,事务A读到了事务B未提交的数据
# 读已提交(Read committed)
Oracle 默认隔离级别 不同的Read View 事务A内部相同的查询语句在不同时刻的结果不一致 不可重复读
# 不可重复读(Repeatable read)
MySQL默认隔离级别 用同一个Read View 事务开始时读取一个快照,之后都是读到这个快照 会导致幻读
# 串行化(Serializable)
解决上面所有问题,包括藏写 已读数据不能被其他事务修改 已读数据不能被其他事务读取 实现原理:读操作加读锁:读操作加读锁select * from account where id = 1 lock in share mode
# 脏写
程序取出来一个值,操作完更新会导致此问题 RR级别下,单条语句加了悲观锁,时有原子隔离性的:update account set balance = balance + 500 where id = 1; RC级别下,需要加version,有乐观锁的:update account set balance = balance + 500 where id = 1 and version = 1;
# 锁
# 锁的分类
# 按性能分
- 乐观锁:每次读取数据时,都认为别人不会修改,所以不会加锁。
- 悲观锁:每次读取数据时,都会加锁。
# 按数据操作粒度分
- 表锁:
- 每次操作锁住整张表
- 开销小,加锁快
- 不会出现死锁
- 锁定粒度大,锁冲突概率高
- 一般在整表数据迁移场景
- 使用方式
- lock tables ... read/write
- unloack tables
- MyIASM不支持表锁
- 每次操作锁住整张表
- 页锁:
- 只有BDB引擎支持
- 比行锁粒度大,开销介于表锁和行锁之间,会死锁
- 行锁:
- 每次操作锁住一行数据
- 需要的时候才加,并不是马上释放,等事务结束才释放
- InnoDB默认行锁,MyISAM不支持行锁
- InnoDB的锁是加在索引对应的”索引项“上的,若索引失效,会从行锁升级为表锁(RR会,RC不会),实际上RR为了解决不可重复读和幻读,加的是间隙锁
- 锁升级
- 1.没有合适的索引,InnoDB会升级为表锁
- 2.显示请求表锁,使用lock tables ... read/write
- 3.某些特性操作,比如DDL
# 按数据操作类型分
- 读锁
- 共享锁:S锁:针对同一份数据,多个操作可以同时进行,不会互相阻塞
- select * from T where 条件 lock in share mode
- 行锁
- 写锁
- 排它锁:X锁:针对同一份数据,不能同时进行
- select * from T where id = 1 for update
- update/delete/insert
- 意向锁
- intention lock,针对表锁,主要为了提高表锁效率
- 当事务给表的数据行加了共享锁或排它锁,同时会给表设置一个标识,表示有行锁了,其他事务想加表锁时,就不必逐行判断
# 间隙锁
两个值之间的空隙,RR下生效 只要在间隙范围内锁住了一条不存在的记录,会锁住整个间隙范围,不锁边界记录,解决幻读
# 临键锁
行锁和间隙锁的组合,间隙锁+边界一起锁住
# MVCC:多版本并发控制
# 做到读写不阻塞,通过undo日志链实现
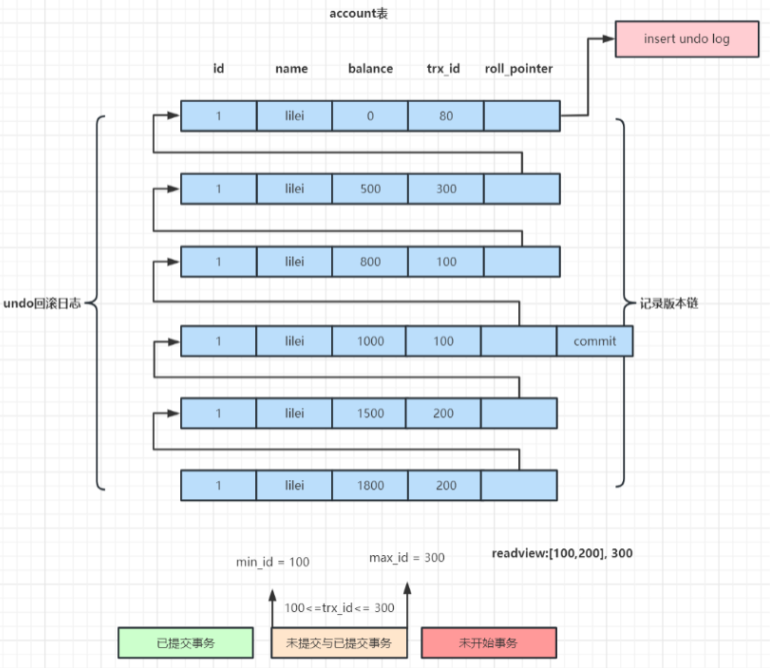
rx_id:事务ID roll_pointer:回滚指针
# read-view:一致性视图
- 由执行查询时所有未提交或已提交事务id数组,即活跃的事务(trx_ids数组里最小的id为min_id)和已创建最大事务id(max_id)组成
- 事务里的任何sql查询结果需要从对应版本链里的最新数据开始逐条跟read-view做比对从而得到最终的快照结果。
- row的trx_id指的是日志链中的trx_id
- 如果 row 的 trx_id 落在绿色部分( trx_id<min_id ),表示这个版本是已提交的事务生成的,这个数据是可见的;
- 如果 row 的 trx_id 落在红色部分( trx_id>max_id ),表示这个版本是由将来启动的事务生成的,是不可见的(若 row 的 trx_id 就是当前自己的事务是可见的);
- 如果 row 的 trx_id 落在黄色部分(min_id <=trx_id<= max_id),那就包括两种情况 a. 若 row 的 trx_id 在视图数组中,表示这个版本是由还没提交的事务生成的,不可见(若 row 的 trx_id 就是当前自己的 事务是可见的); b. 若 row 的 trx_id 不在视图数组中,表示这个版本是已经提交了的事务生成的,可见。
- 对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,然后将trx_id修改成删除操作的 trx_id,同时在该条记录的头信息(record header)里的(deleted_flag)标记位写上true,来表示当前记录已经被删除, 在查询时按照上面的规则查到对应的记录如果delete_flag标记位为true,意味着记录已被删除,则不返回数据。
- 参考:https://www.cnblogs.com/EthanWong/p/15969528.html
- read-view和可见性算法其实就是记录了sql查询那个时刻数据库里提交和未提交所有事务状态。 要实现RR,事务里每次执行查询操作read-view都是第一次查询时生成的read-view,都以第一次查询时所有事务提交状态来对比数据是否可见。 要实现RC,事务里每次执行查询操作read-view都会按照数据库当前状态生成read-view,每次查询都跟数据库里当前所有事务提交状态来对比数据是否可见。
# select操作时快照读(历史版本)
# insert,update,delete操作时当前版本
# RC语句级快照
# RR事务级快照
# MySQL日志
# undo log:回滚日志
通过undo log记录数据修改前的状态,实现事务的原子性,通过mvcc保证事务隔离级别
# redo log:重做日志
通过redo log记录数据修改后的状态,实现事务的持久性,通过WAL机制保证事务的持久性
# binlog:归档日志
通过binlog记录数据修改后的状态,实现mysql的增量备份和主从复制
# 常见问题
# 回表
回表是在数据查询过程中通过非主键索引找到数据行后,再通过主键索引去获取完整行数据的过程
如何避免:
- 使用覆盖索引:确保查询所需的所有字段都包含在索引中,这样查询就可以仅通过访问索引来完成,无需回表
- 优化查询语句:避免在查询中包含不必要的列,尤其是那些不在索引中的列
- 创建联合索引:如果查询经常同时涉及到多个字段,可以考虑创建一个包含这些字段的联合索引
# 规范
# 1. 建表相关规范
1.库名、表名、字段名,使用小写和下划线 _ 分割
2.库名、表名、字段名,不超过12个字符。默认支持64个字符。
3.库名、表名、字段名,见名知意,建议使用名词而不是动词。
4.使用 InnoDB 存储引擎。支持;事务、锁、高并发 性能好。
5.推荐使用 utf8mb4 可以存emoji
6.单表字段数,建议不超过40个
# 2. 字段相关规范
1.整型定义中不显示设置长度,如使用 INT,而不是INT(4)
2.存储精度浮点数,使用 DECIMAL 替代 FLOAT、DOUBLE
3.所有字段,都要有 Comment 描述
4.所有字段应定义为 NOT NULL
5.超过2038年,用DATETIME存储
6.短数据类型 0~80 选用 TINYINT 存储
7.UUID 有全局唯一统一字段属性,适合做同步ES使用。
8.IPV4,用无符号 INT 存储
9.IPV6,用VARBINARY存储
10.JSON MySql 8.x 新增特性
11.update_time 设置 on update 更新属性
# 3. 索引相关规范
1.要求有自增ID作为主键,不要使用随机性较强的 order_id 作为主键,会导致innodb内部page分裂和大量随机I/O,性能下降。
2.单表索引建议控制在5个以内,单索引字段数不超过5个。注意:已有idx(a, b)索引,又有idx(a)索引,可以把idx(a)删了,浪费空间,降低更新、写入性能。* 单个索引中,每个索引记录的长度不能超过64KB
3.利用覆盖索引来进行查询操作,避免回表。另外建组合索引的时候,区分度最高的在最左边。
4.select(count(distinct(字段)))/count(id) = 1 的区分度,更适合建索引。在一些低区分度的字段,例如type、status上建立独立索引几乎没意义,降低更新、写入性能。
5.防止因字段不同造成的隐式转换,导致索引失效。
6.更新频繁的字段,不要建索引。
# 4. 使用相关规范
单表数据量不超过500万行,ibc 文件大小不超过 2G
水平分表用取模,日志、报表类,可以用日期
单实例表数目小于 500
alter表之前,先判断表数据量,对于超过100W行记录的表进行alter table,必须在业务低峰期执行。因为alter table会产生表锁,期间阻塞对于该表的所有写入
SELECT语句必须指定具体字段名称,禁止写成 “*”select * 会将不需要读的数据也从MySQL里读出来,造成网卡压力,数据表字段一旦更新,但model层没有来得及更新的话,系统会报错
insert语句指定具体字段名称,不要写成 insert into t1 values(…)
insert into…values(XX),(XX),(XX).. 这里XX的值不要超过5000个,值过多会引起主从同步延迟变大。
union all 和 union,不要超过5个子句,如果没有去重的需求,使用union all性能更好。
in 值列表限制在500以内,例如 select… where userid in(….500个以内…),可以减少底层扫描,减轻数据库压力。
除静态表或小表(100行以内),DML语句必须有where条件,且尽量使用索引查找
生产环境禁止使用 hint,如 sql_no_cache,force index,ignore key,straight join等。 要相信MySQL优化器。hint是用来强制SQL按照某个执行计划来执行,但随着数据量变化我们无法保证自己当初的预判是正确的。
where条件里,等号左右字段类型必须一致,否则会造成隐式的类型转化,可能导致无法使用索引
生产数据库中强烈不推荐在大表执行全表扫描,查询数据量不要超过表行数的25%,否则可能导致无法使用索引
where子句中禁止只使用全模糊的LIKE条件进行查找,如like ‘%abc%’,必须有其他等值或范围查询条件,否则可能导致无法使用索引
索引列不要使用函数或表达式,如 where length(name)=10 或 where user_id+2=1002,否则可能导致无法使用索引
减少使用or语句 or有可能被 mysq l优化为支持索引,但也要损耗 mysql 的 cpu 性能。可将or语句优化为union,然后在各个where条件上建立索引。如 where a=1 or b=2 优化为 where a=1… union …where b=2, key(a),key(b) 某些场景下,也可优化为 in
分页查询,当limit起点较高时,可先用过滤条件进行过滤。如 select a,b,c from t1 limit 10000,20; 优化为 select a,b,c from t1 where id>10000 limit 20;
同表的字段增删、索引增删等,合并成一条DDL语句执行,提高执行效率,减少与数据库的交互。
replace into 和 insert on duplicate key update 在并发环境下执行都可能产生死锁(后者在5.6版本可能不报错,但数据有可能产生问题),需要catch异常,做事务回滚,具体的锁冲突可以关注next key lock和insert intention lock
TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE 无事务且不触发 trigger ,有可能造成事故,故不建议在开发代码中使用此语句。说明: TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同。